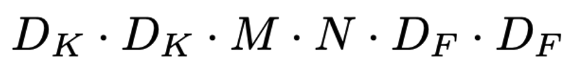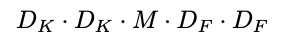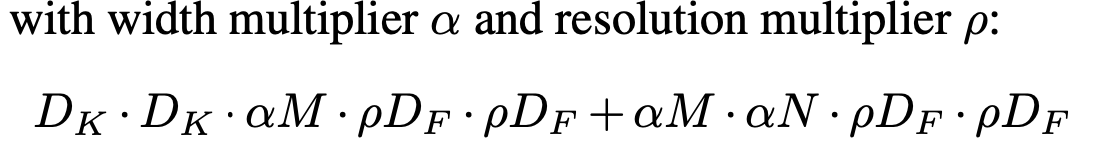해당 paper는 mobile과 embedding vision application에서 적용 가능한 efficient한 모델인 MobileNets을 제안
MobileNets은 가벼운 DNN을 만들기 위해 depth-wise seperable convolution을 수행
latency와 accuracy 사이의 trade-off를 조절하기 위해 두 개의 hyperparameter를 제시
여러가지 use-case에서 MobileNet의 효과를 봄
1. Introduction
Alexnet 이후 accuracy는 엄청 높이기 위해 모델이 구조가 더 deep하고 복잡해짐
그러나 모델이 정확도가 좋은 것과 별개로, 모델의 size와 speed 측면의 효율성은 떨어짐
그러나, 로보틱스 or AR등의 현실세계인 모바일이나 임베디드의 제한된 computation platform에서 구동될 모델들이 이런 모델로 수행하긴 어려움
해당 paper에서는 hyperparameter 두 개로 모델의 성능(사이즈)을 선택할 수 있는 모델을 제시
즉, 해당 모델은 개발자가 직접 제한된 resouce에 맞는 network size의 모델을 사용할 수 있도록 함
2. Prior Work
모델을 경량화 연구는 크게 두 가지
큰 사이즈로 Pretrained된 모델의 Network를 압축하는 경우
처음부터 소규모 네트워크를 직접 학습하는 경우
모델 사이즈를 줄이는 이전에 많은 모델들
Inception, Xception
모델을 Compression 하는 기법
qunatization, pruning, 등등 기법들..
그러나 해당 paper는 이전 연구들고 다르게 제한된 resource에서 latency와 size를 직접 결정할 수 있는 network architecture
3. MobileNet Architecture
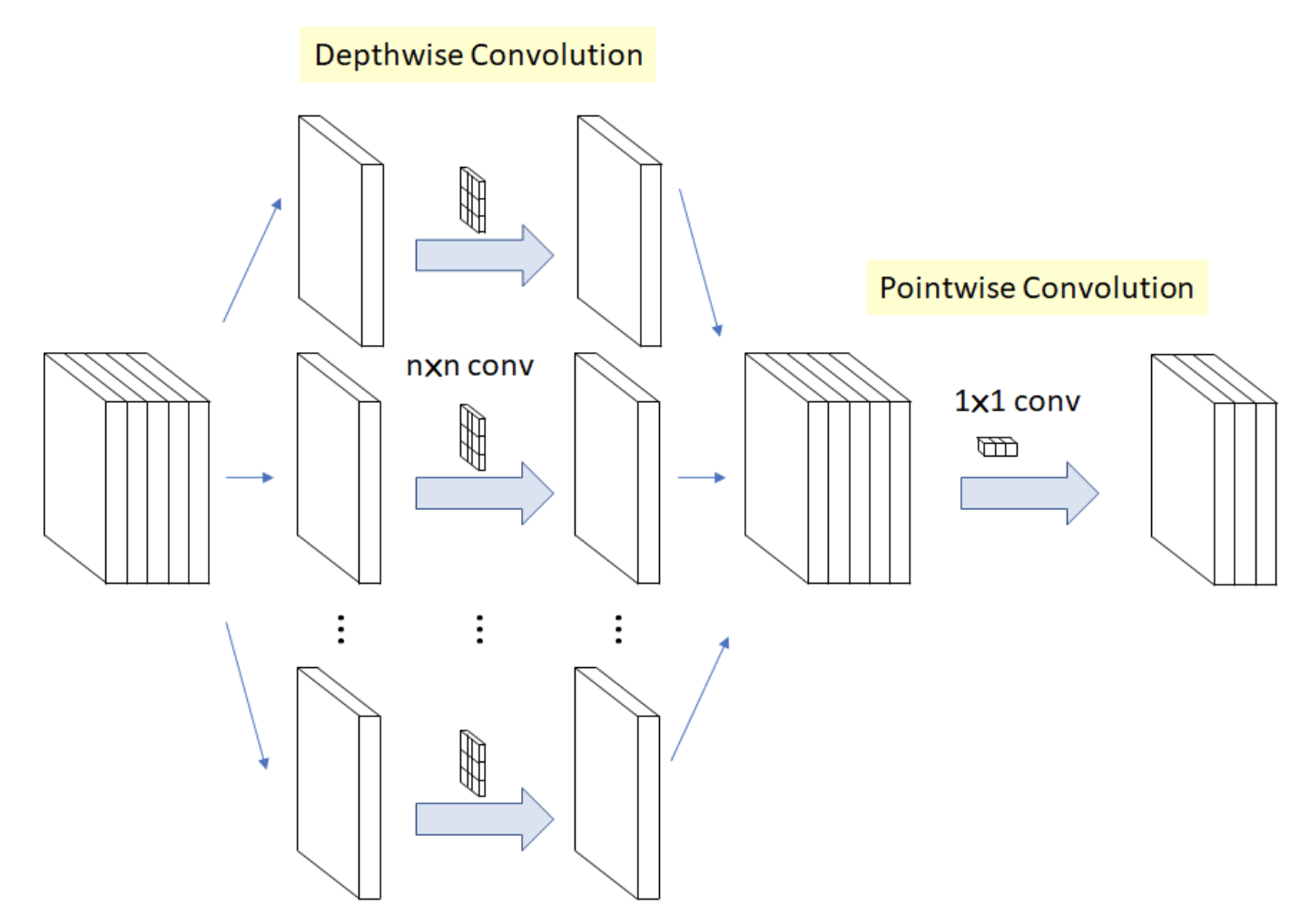
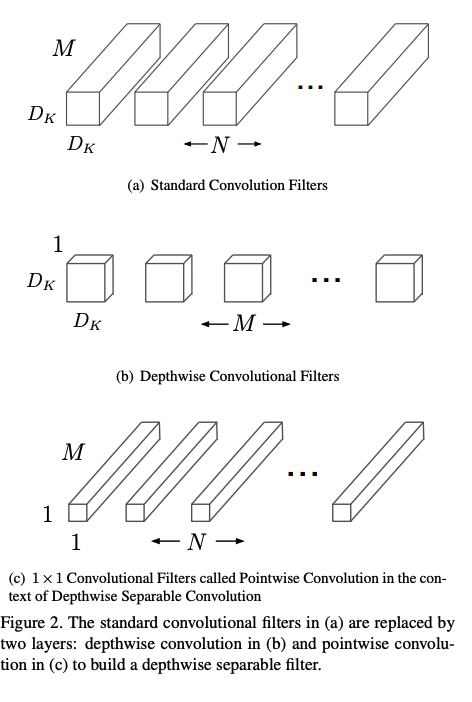
MobileNet은 standard convolution을 depthwise convolution와 1x1 convolution(=point wise conovolution)으로 분리(=factorization)하여 연산을 수행함
따라서 연산량을 엄청 감소시킴
기존 standard conv의 경우 전체 연산량은 다음과 같음
Dk는 입력값의 크기(가로, 세로)
M은 입력의 채널 수
N는 출력 채널의 수
Df는 FM의 크기(가로, 세로)
1) Depthwise convolution
Depthwise convolution은 각 입력의 채널마다 채널별 1개의 필터를 적용하는 것
각 input channel에 대해 3x3 conv 하나의 필터가 연산을 수행하여 하나의 Feature Map을 생성함
입력 채널 수가 M개면 M개의 FM을 생성
각 채널마다 독립적으로 연산을 수행하여, spatial correlation을 계산
예를 들어, 5개 채널의 입력값에, 5개의 3x3 conv가 각 채널에 대해 연산을 수행하고, 5개의 FM을 생성함
다음은 연산량의 식
Dk는 입력값의 크기
M은 입력의 채널 수
Df는 FM의 크기(가로, 세로)
2) Pointwise convolution
depthwise에서 생성한 FM들을 1x1 conv로 output 채널 수를 조정함
1x1 conv는 모든 채널에 대해서 연산을 수행하므로, cross-channel correlation을 계산하는 역할
다음은 연산량의 식
M은 입력 채널 수
N는 출력 채널 수
Df는 FM의 크기 (가로, 세로)
3) 전체 연산량
3x3 depthwise separable conv를 하면 기존 standard conv보다 연산량이 8~9배 정도 줄어듦
4. Network Structure and Training
왼쪽은 Strandard Conv의 구조, 오른쪽은 Depthwise seperable Conv의 구조
궁금증 ? [ 왜 Depthwise Conv 이후에 BN, ReLU가 있나요? ] - Depthwise Convolution 후에 BN, ReLU가 있는 이유는 각 채널별 필터링 결과에 안정성과 비선형성을 부여하여 더 복잡한 특징을 추출하기 위함 [ 왜 Pointwise Conv 이후에도 BN, ReLU가 있나요? ] - 채널 간의 상호작용을 한 후에도, 출력이 안정적이면서도 비선형을 유지하여 더 풍부한 특징을 학습하기 위함
MobileNet의 Depthwise 연산으로 충분히 작고 latency를 가지게 되었지만, 특정 task에서 더 빠른 모델이 필요할 수 있음
MobileNet은 모델의 latency와 accuracy를 조절하는 두 개의 hyperarameter가 있음
1) Width Multiplier : Thinner Models
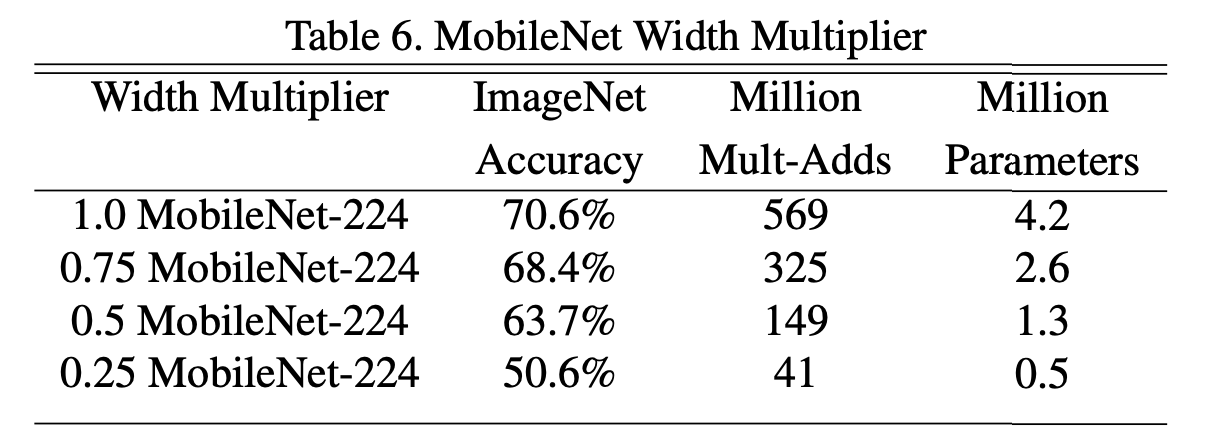
해당 hyperparameter인 α는 model의 두께를 결정
α는 0에서 1사이, 대체적으로 1, 0.75, 0.5, 0.25 사용(1이 base)
여기서 두께란 각 layer에서 filter의 수를 의미함
α는 입력 채널에 각각 곱해져 전체적인 채널 수를 줄여 parameter와 computation cost을 감소시킴
더 얇은 모델이 필요할 때, 입력 채널 M과 출력 채널 N에 적용하여 αM, αN이 됨
각 α에 맞춰 진행한 실험 결과는 다음과 같음
2) Resolution Multiplier: Reduced Representation
해당 hyperparameter인 ρ는 입력 이미지에 곱하여 전체 모델의 연산량을 감소시킴
ρ는 입력 이미지에 적용하여, 해상도를 낮춤
ρ의 범위는 0~1(1이 base)
연산량은 다음과 같으며, 논문에서 이미지 크기가 224, 192, 169, 128 일때를 비교함
3) 두 개의 hyperparameter 적용
5. Experimentals
1) Model Choices
depthwise separable한 경우 일반적인 full conv에 비해 accuracy가 1퍼정도만 줄음
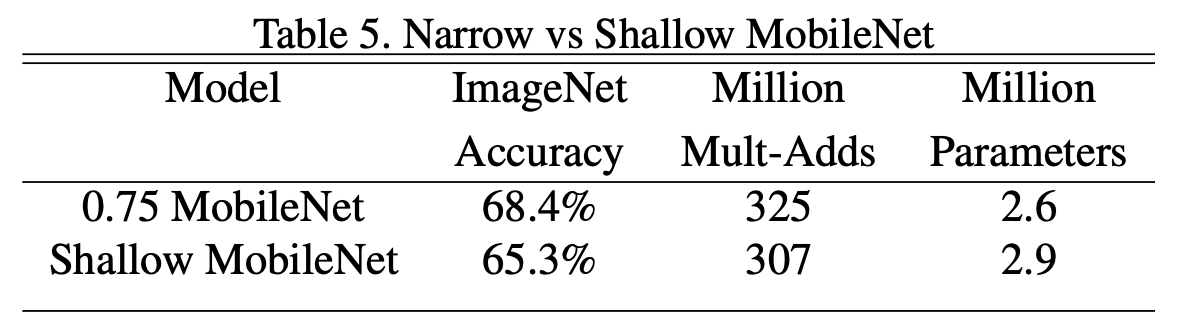
비슷한 연산량과 파라미터를 가진 Shallow MobileNet(depth를 줄임)보다 조절한 0.75 MobileNet(Narrow MobileNet)이 성능 더 나음
Shallow MobileNet은 중간에 pooling 없이 연산되는 5개의 층을 제외해 경량화 시킨 것
2) Model Shrinking Hyperparameters
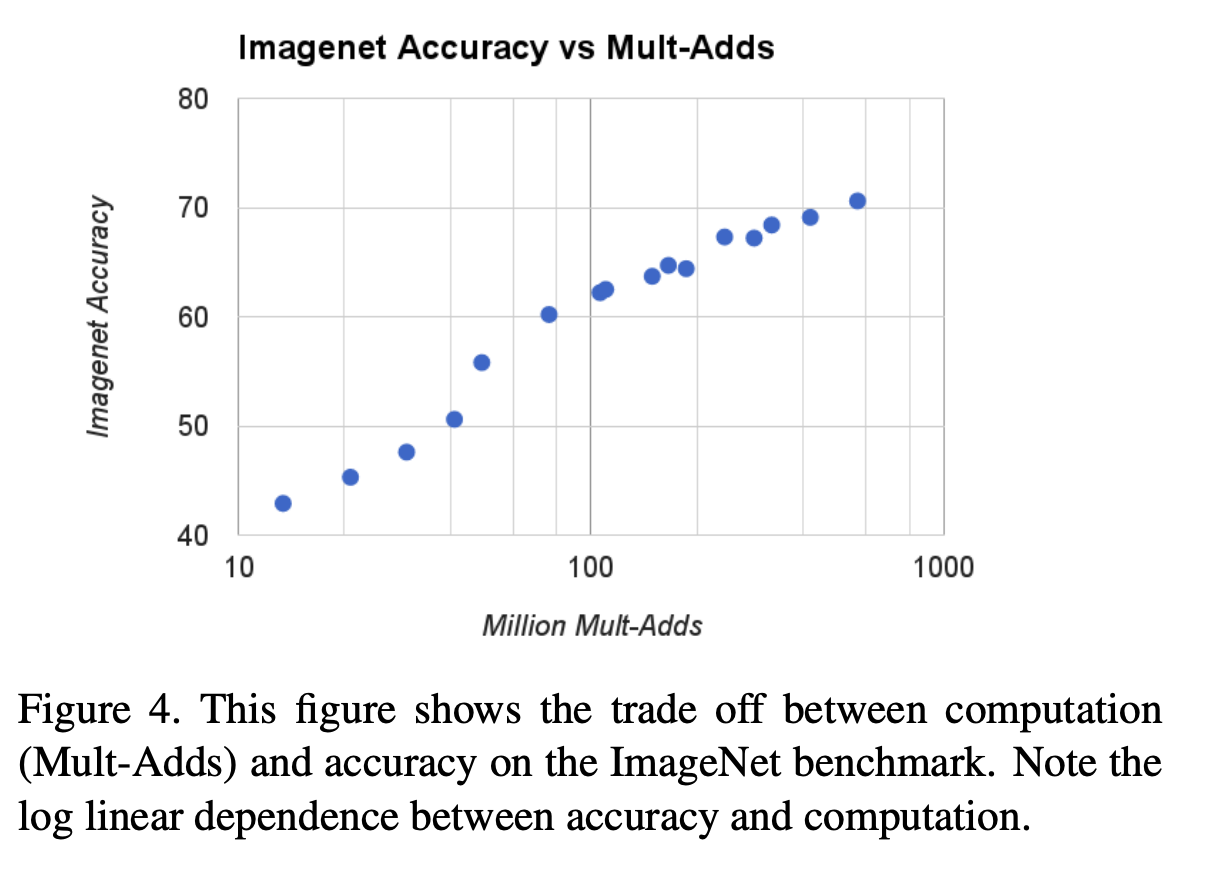
accuracy와 computation의 trade-off
16 model
α = { 1, 0.75, 0.5, 0.25 }
ρ = { 224, 192, 160, 128 }
log linear함( α = 0.25에서 점프..)
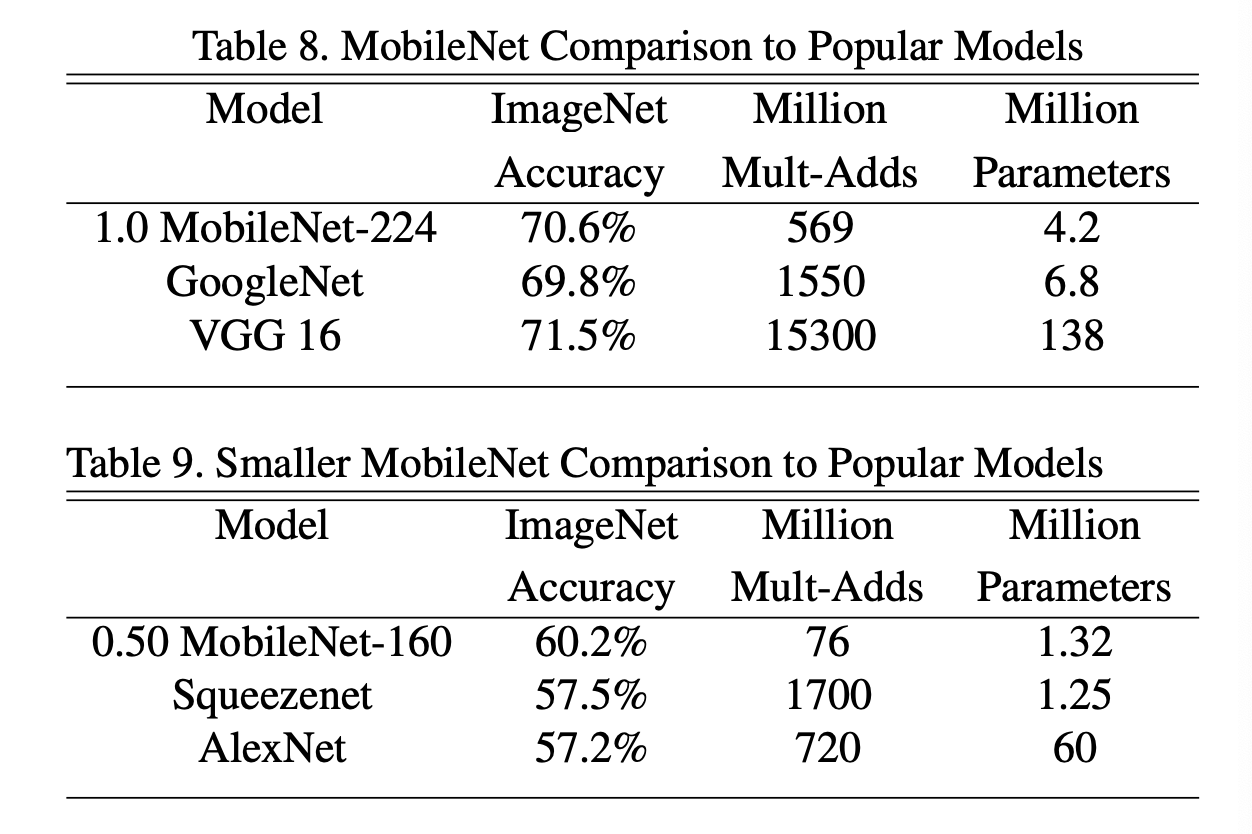
다른 유명 모델들과의 비교
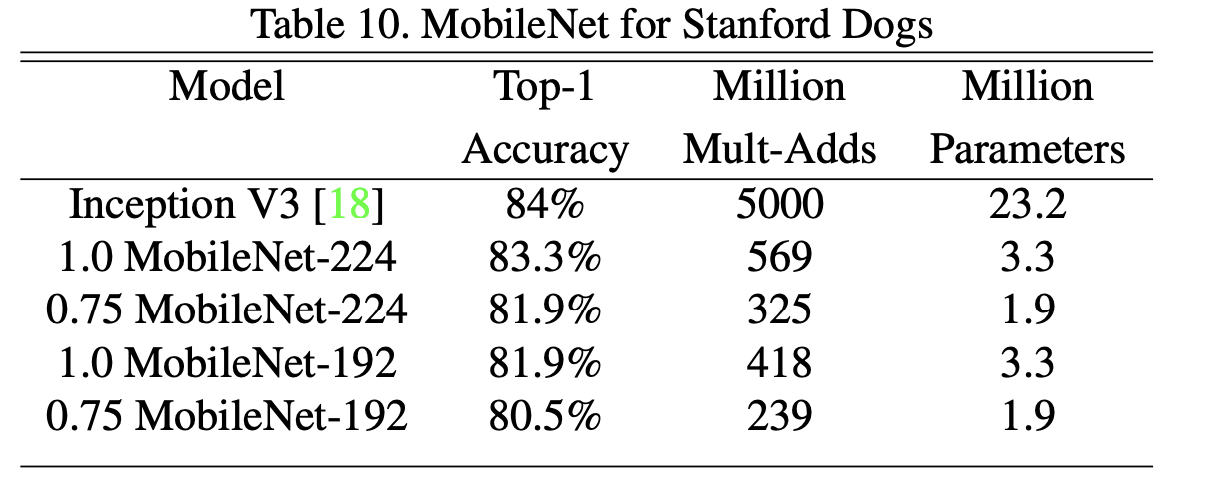
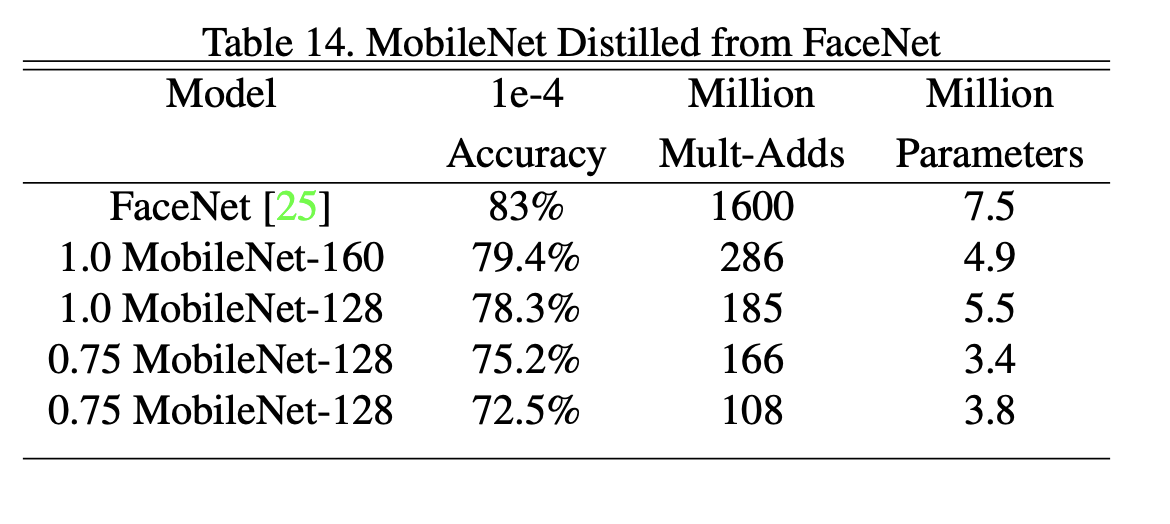
3) Fine Grained Recognition
noisy한 web data로 pretrain하고, Strandard Dogs training set으로 model을 fine tune
mobilenet model을 거의 좋은 성능을 달성함(computation, model size 고려해도)
![[AI] MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications 논문 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbbWWO8%2FbtsJCZD3cMO%2F6Lu0XsR92TFK61tVwnrCW0%2Fimg.png)